Abstract
Vision-Language-Action (VLA) systems have shown strong potential for language-driven robotic manipulation. However, scaling them to long-horizon tasks remains challenging. Existing pipelines typically separate data collection, policy learning, and deployment, resulting in heavy reliance on manual environment resets and brittle multi-policy execution. We present RoboClaw, an agentic robotics framework that unifies data collection, policy learning, and task execution under a single VLM-driven controller.
At the policy level, RoboClaw introduces Entangled Action Pairs (EAP), which couple forward manipulation behaviors with inverse recovery actions to form self-resetting loops for autonomous data collection. This mechanism enables continuous on-policy data acquisition and iterative policy refinement with minimal human intervention. During deployment, the same agent performs high-level reasoning and dynamically orchestrates learned policy primitives to accomplish long-horizon tasks.
By maintaining consistent contextual semantics across collection and execution, RoboClaw reduces mismatch between the two phases and improves multi-policy robustness. Experiments in real-world manipulation tasks demonstrate improved stability and scalability compared to conventional open-loop pipelines, while significantly reducing human effort throughout the robot lifecycle, achieving a 25% improvement in success rate over baseline methods on long-horizon tasks and reducing human time investment by 53.7%.
What can we do?
Automatic Data Collection
What if the automatic data collection fails?
Execute long-horizon tasks
What if we want to execute the task remotely?
Long-horizon tasks with only dual arms
What if we want to expand the workspace?
The dataset we collect


Overview of RoboClaw
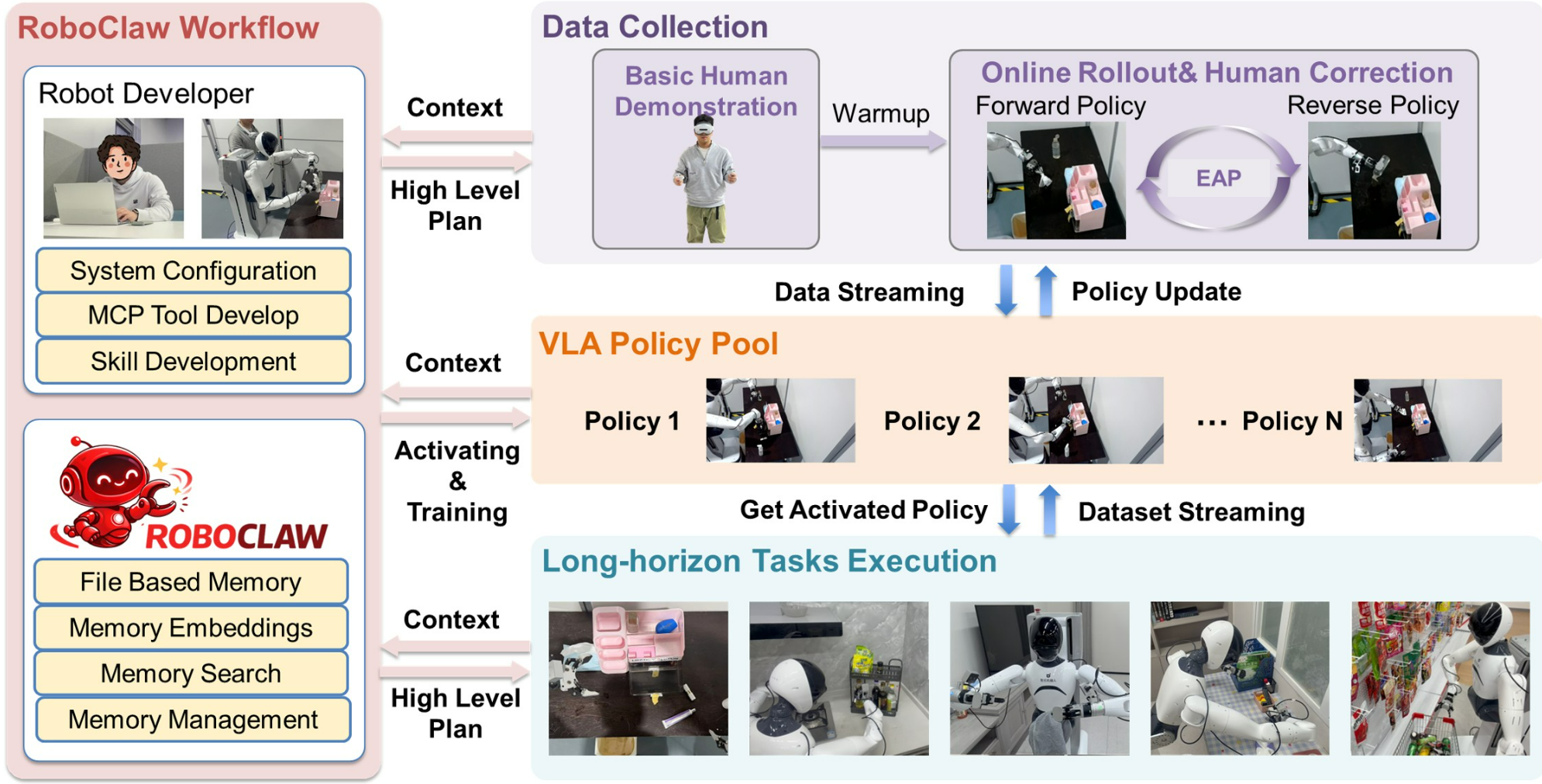
RoboClaw workflow across the robot policy lifecycle. A robot developer specifies system configuration, MCP tools, and skills, while RoboClaw provides file-based memory, memory embeddings, search, and management. Data is collected through basic human demonstrations followed by online rollout with EAP self resetting, producing a VLA policy pool that is continuously updated via streaming data. Activated policies are then used to execute complex long-horizon tasks under high-level plans and contextual guidance.
Performance demonstrated by data
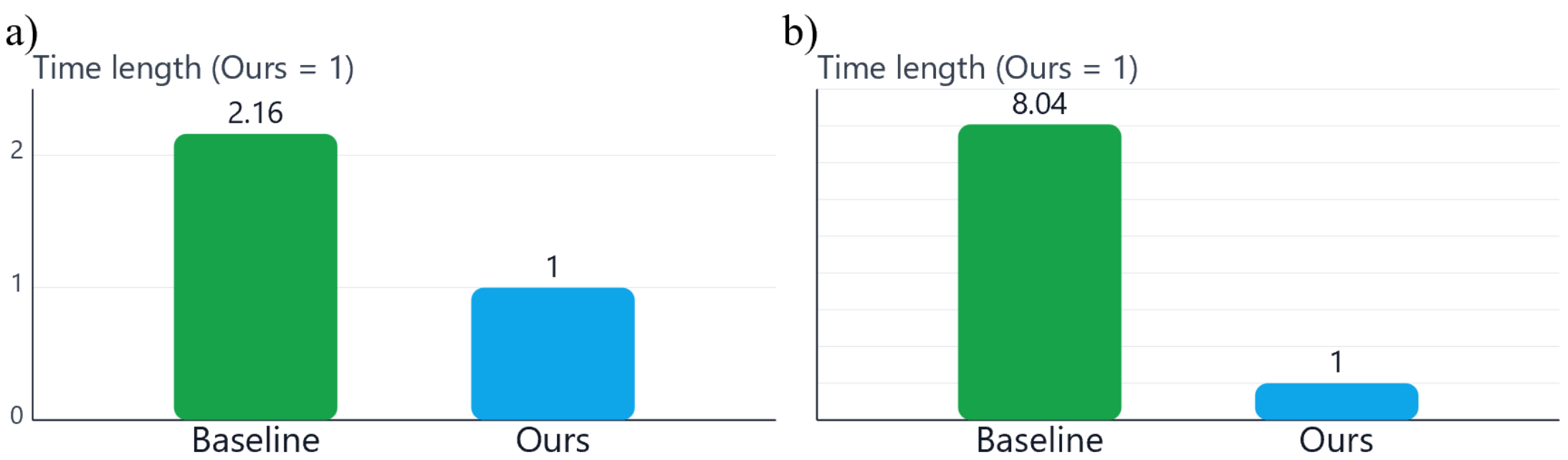
Human effort comparison for data collection. (a) Relative human time required to collect the same amount of data. (b) Relative human intervention during rollout execution. All values are normalized with respect to our method (Ours = 1).
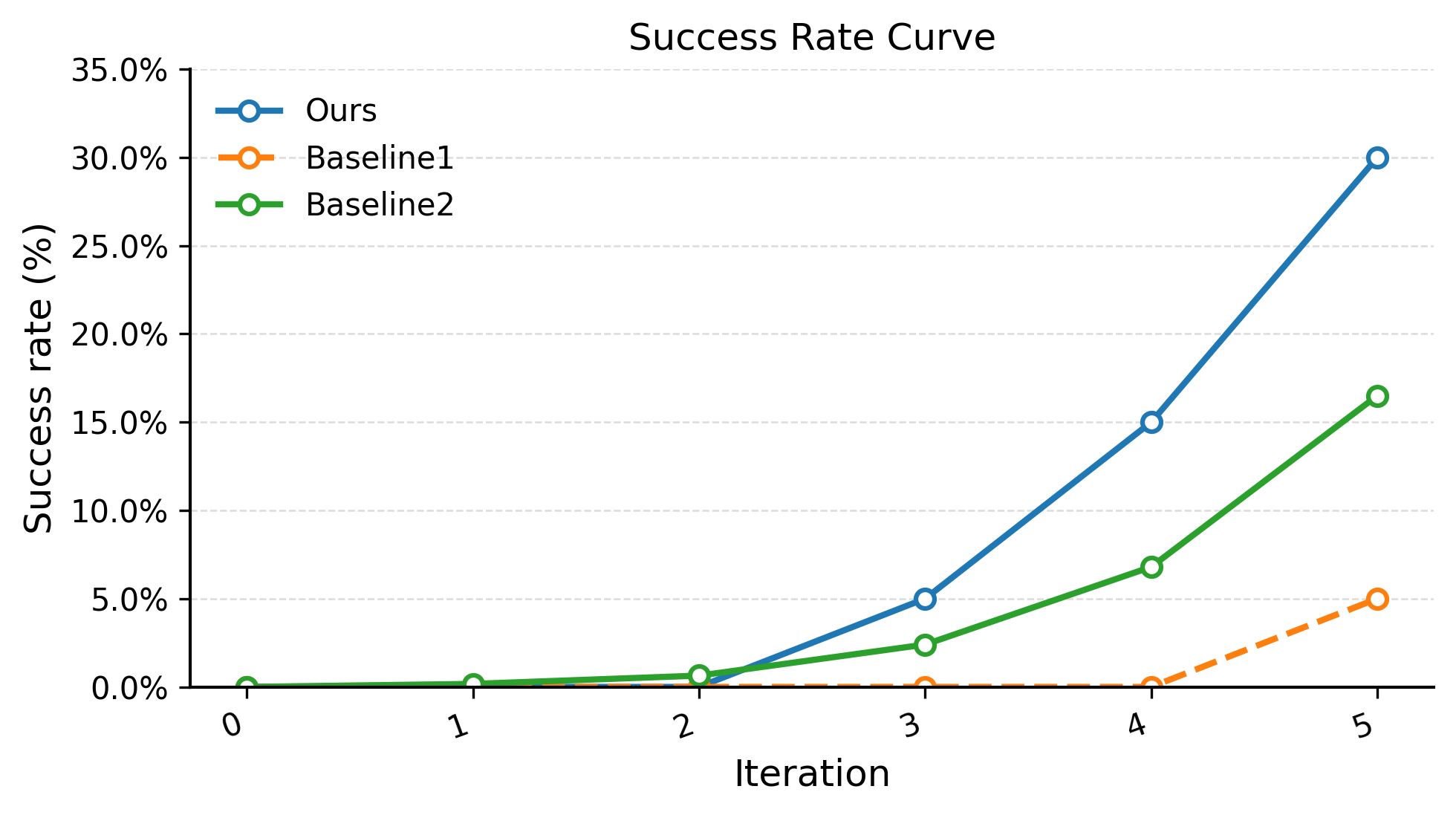
Success rate across iterations on the vanity table organization task. RoboClaw (Ours) significantly outperforms both end-to-end VLA baselines and the expected success rate computed as the product of four independent subtask success rates. The improvement comes from RoboClaw’s ability to monitor task progress and automatically invoke recovery policies when failures occur. Results are averaged over 20 trials.